

table of contents
 Mapping out this rabbit hole, zigzagging over the boundary between art and computer science, getting distracted by Stable DIffusion along the way.
Mapping out this rabbit hole, zigzagging over the boundary between art and computer science, getting distracted by Stable DIffusion along the way.
This is part 3 of introductory posts, that explain the context and reasons
for starting "Diffusion Pilot", while also delving into some technicalities.
Catch up from part 1, or go deeper in level 3 posts and Diffusion Pilot itself.
Back around mid 2010s, as technology of deep learning (DL) research was
opening up to individual experimenters, it brought the dawn of new bizarre AI
aesthetics:
Do not let Google's Deep Dream code have access to gifs. The things it
makes with them are terrifying.
For a digital experimental animation, this was clearly intriguing. These were neural networks dealing with static image data, but making rudimentary animation was just a matter of stitching enough of those images together. The results of that were often flickery, untamed psychedelic snippets.
But as is the case with most technology research, the goals were straightforward and utilitarian: human-like vision comprehension, or generating effortless, indistinguishable-from-real images. Static AI images are arguably already there in 2023. However, for art, the path to that may be more intriguing than the goal. All the glitchy, faulty in-betweens of this evolution, exposing entirely new forms of manifesting visuals. I followed that wild experimental phase closely, hesitating to deep dive into it, possibly fearing something I could never come back from.
Some years pass, and here I am blogging about it 💫
While this blog mostly deals with Stable Diffusion and related techniques, in this final "Intro" post I'll remember my path of search and learning before everything was as approachable as it is now, from the perspective of stubborn but mostly clueless animator, crossing over disciplines - from art into deep learning. I must stress that this post is not an expert guide in the field of computer science, but rather a subjective story of jumping into this rabbit hole as an outsider, and reporting back about the most interesting findings that concern the visual arts.
Deeply learning about deep learning (DL)
In the beginning of my search and research, with Stable Diffusion yet to be released, I knew I'd be confronting some sort of neural networks that deal with images to fulfill my concept and desired aesthetics for an animated film, but had concluded that I would need to get hands on with such tech to comprehend it deeply and achieve desired creative control. My first major breakthrough was discovering the work and related PhD paper of "Learning to see", that shines a light on a technical approach to DL that was deeply integrated with artistic mindset.
Soon after, with perfect timing, an email pops up in my school inbox offering some remote courses, one of them being "introduction to deep learning".
It was a dense, technical course that couldn't exist in such a shape and form in an art Academy like EKA where I studied, offered remotely through "Transform4Europe" project, so I felt extremely grateful for it. I didn't know much of DL at that point, but within this field I was fixated on GANs, which is a type of neural network architecture that was driving the new wave of image generation advancements at that time. This was early summer of 2022, I was aware of "Google Colab" being a popular option to interface with development and usage of DL, but it felt rather intimidating to an amateur enthusiast. There were user-friendly templates and demos, but I had no idea how to take it from there, customize it, make an entire film using it.

Google Colab is a bit like Google Docs suite, designed for running code on powerful machines remotely. "Notebooks" designed to run AI applications are freely shared within community in an open source spirit.
Throughout 5 to 6 hours of deep dive lecturing the teacher forgot only one thing - to have a break, but I was damn excited. The copious amount of material was challenging to take in, but it felt like finally taking the first steps into this rabbit hole, with the guidance of the teacher trio. I got familiarized with the fundamentals and core structure of DL, and got to chew on tasks with aforementioned Google Colab, using Python and TensorFlow. It was deeply satisfying seeing tiny little models, simplified for educational purposes, learn to classify images of clothing, hand drawn numbers, or generate entirely new images on my command.
My confidence got inflated, I was getting ready to art the shit out of these neural networks.
Well, I thought I will work my way up to something profound and compelling, but first, after finishing the short course, I still had to practice.
Make me a triangle
To keep learning about
GANs, I came up with an
extremely basic task to act as a learning ground for me and my first practice
GAN model. To put it
simply, a GAN is meant to
generate images that match the characteristics of images it was trained on.
Using simple randomization in After Effects, I generated a bunch of predefined
shapes in random colors and compositions, like this:

Later I simplified it even more, narrowed down to centered regular triangles of random color, size and rotation:

This would be the training data, and subsequently the goal to generate similar images from a little GAN model. My lack of any computer science background hindered the pace of my progress, but thankfully I had the patience for it, and TensorFlow acted as a generous abstraction layer over heavy low level engineering that executes deep learning tasks. It's a code library offering neatly organized "boxes" of DL machinery, although you're still responsible to pass in valid data, interpret and display it correctly, and chain it all together following adequate logic and architecture. Doable for a non trained artist with some warmup, but only if you tend to be more tech savvy.
After some iterations and also learning to log and save the training process itself, I was able to visualize it like this:
In this graph, each "epoch" the two competing networks in a GAN update their "weights" to try and improve their behavior, with their success measured by the "loss" function that gives a rating (smaller number is better). It's also a timelapse, with a few sample images from the generator at that point in training (seen at the top). Generally, each neural network starts with random weights and thus gives random results (noise) at first, then if successful, gradually picks up on the data. Logging training process like this is a fun way to observe your little personal GAN absolutely suck, or eventually get to generating some crunchy looking rainbow Doritos.
Taking a walk in the latent space
Plugging 50,000 portraits into facial recognition/emulation software can generate some pretty fascinating nightmare fuel.
by u/sianner18 in Damnthatsinteresting
A type of animation that is truly unique to the medium of generative neural networks, and in turn GANs, is interpolation between points in the latent space of a model. Way simplified, a latent space is basically the entire possibility space of a generative neural network model. When you generate a new image with the generator from a GAN, it will do it based on a "seed". Same seed will always give the same result, and to produce a whole bunch of generated images, you'd just roll a random seed for each one. Now, compared to say a 6-sided dice, that has limited possibilities of exactly 6, a generator can work with anything in-between. The equivalent dice would simply be ball, that freely rotates between the 6 numbers. There is an image for "1" and "2", but there are also any amount of intermediate images between "1" and "2".
Try it yourself!

So basically the latent space is made up of all the possible seeds. "Walking" in this space means taking small steps in it and seeing how the generated output changes gradually, as points in this space close together also produce similar generated results. This is a very simplified explanation, and the latent space in practice is a very multi-dimensional space, instead of a single number. Researchers have been able to map meaningful characteristics to specific distributions in this latent space, such as features of a face in a GAN trained on faces, but for now, I simply made my rainbow Doritos morph between random points in the latent space :)

Film Director - AI Conditioner
After all this warmup, I was ready to get closer to what my film would actually require. Inspired by the aforementioned "Learning to see", that was dealing with ways to introduce intent and control into generative AI, I had my eyes on "Pix2Pix" (from 2016), best Illustrated by the viral "Edges2Cats" demo.
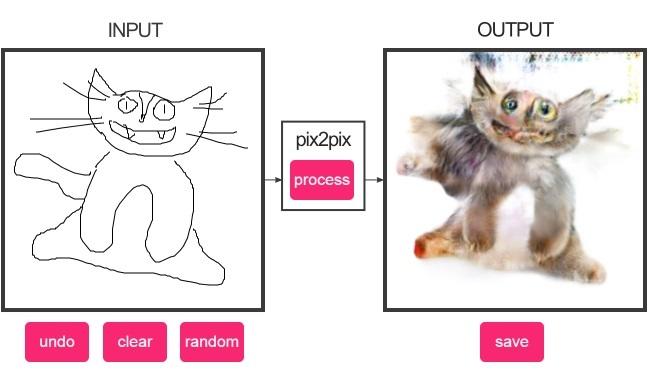
The "Conditioner" points not to AI hair-care, but to conditioning a neural network model, like a GAN. It's about influencing its otherwise random generated result with a specific condition, which in this case is an image. You give an image, you get an image, processed based on the the training data of the model. For that demo, it was trained on cat photos, and their corresponding line-only pictures, or "edges", each being perfectly paired. The model knows nothing but "cat-ness", so inputting even random squiggles will force it to generate blobs of cat-like fur and occasional eyes.
Cool! So where is this going?
As an artist, if you were to prepare your own data of input/output pairs,
you could train your own model to do tasks based on your visual direction. In other words, directing the AI to endlessly slave away coloring or painting
your animation frames.
In my case though, I wasn't necessarily into cheating my way out of work, as discussed in Part 2 of intro. I was more interested in the "loss-in-translation" aspect between my inputs and model's outputs, loosely directing the composition of each frame in my animation, yet allowing the model to lose grip on the precise details and introduce the oh so desired ambiguity that I riff on in Part 1 of intro. I was to supply it with some sort of rudimentary sketches, and it was to "paint" them in each frame.
As a proof of concept, I arrived at this sort of test training data:

Once again I was generating random samples automatically, preparing thousands of pairs with outputs being simple textured walls in 3D space with some fog, and inputs being same exact walls but with a simple hatched texture instead, all from (matching) random camera angles. Essentially the model was supposed to learn to perceive 3D planes in space and paint the texture with correct orientation and appropriate depth of field created with fog. This model wasn't dealing with actual 3D data, but only 2D pixel representations of it - simple images.
Once again I visualized the training process through a timelapse:

to benchmark the model as it trains

Here I was training texture and fog output as separate channels, so they're visualized separately. Each frame of the gif representing a snapshot state of the model, just like in the last example. Here however, the training seems to never converge on a stable state, after certain point adjusting itself with seemingly no further improvements.
And here's me trying the trained model on a simple fly-through animation with some of those 3D hatched planes:


While this was only a test, I was imagining a similar principle to be used in the actual film production. The inputs after training don't necessarily have to be 3D rendered images, as you could simply hand-draw similar looking hatched surfaces and have the model interpret it into 3D spaces with depth. The element of some miscommunication is expected and indented, between the animation director (me), and the "dreamer" (the AI model) trying to build it into images by digitally painting the sketches. This element of flicker, "indecisiveness" of images frame-after-frame, the odd organic plasticity of visuals were right up my alley and one of the goals of my entire Master's thesis, but it was still a long road ahead.
Outpaced by the progress
After a good streak of technical progress I had to take a break and focus on narrative, story-boarding, and other parts of film production. Long story short, I never really came back to it. My Google Colab notebooks started collecting dust. The end of 2022 and then 2023 was an explosion of all kinds of AI advancements. My humble GAN exercises have gotten kind of irrelevant, as advanced text2image AI were taking over the world. I had my reasons and feelings for ignoring it though, as covered in this Intro series, until...

...until I discovered "ControlNets", a relatively recent advancement at that time (April 2023). I was working in Blender for my film, and was looking into "Dream textures" add-on to finally try out Stable Diffusion with minimal setup, however it was pretty basic at first. ControlNets were implemented later in an update, together with some demo videos. That completely sold it to me, as I realized that the workflow between 3D software and SD can become extremely interconnected and supercharged with this innovation.
The essence of ControlNets is simply "Control", corresponding to "Conditioning" discussed earlier, or "Directing" if thought in terminology of film making. Initially presented through a research paper, it expanded into a whole philosophy of "injecting" control into the diffusion process. It quickly made its way into user-ready applications based on Stable Diffusion in forms of conditioning through a variety of image data, such as depth, edges (just like "Edges2Cats"), normal maps, character poses, and more. With one broad stroke it covered all of my imagined image-to-image workflows that I was prototyping earlier through older DL architectures.
This was my first test inside Blender with Dream Textures, using a "depth" ControlNet:
With Dream Texture's "Render engine" you could plug in live data as ControlNet input, supplying something like
depth map directly from your 3D scene, which is what I did here. A depth map
is simply an image with grayscale values corresponding how close or far each
point is. (not actually shown in this example though)
The text prompt for this test was "backrooms" along with some other phrases.
While not exactly a shot from my film, it does reflect most of my desired
use cases. I started envisioning a workflow, where I could construct rough
layouts for scenes and create a detailed camera movement through them.
Without doing detailed 3D modelling and texturing, I could have Stable
Diffusion "dream" up the actual animation frames, using ControlNets to
guide the diffusion process akin to directing. It is by no means high fidelity
or photorealistic, but if you've been reading anything else I was writing,
you'll know I actually want it kind of wonky, dreamy, and uncanny.
This test had very poor temporal consistency though, but I was already aware of potential methods to work with that. Even in the days of primitive style transfer with GANs, there were techniques to "stick" the generated textures onto surfaces using optical flow, as seen in this early experimental video. With Stable Diffusion, a common methodology is to form feedback loops by sending result of each frame as an image2image input for the next frame.
But that's it, I was hooked. The AI progress is recklessly marching forward, there are ways to generate entire clips of video from text, but I have decided to settle on animating Stable Diffusion for my film and really explore it beyond it being just a flickering gimmick. I've discovered Deforum, WarpFusion, and other tools for video/animation work with Stable Diffusion, but I was compelled to spin off my own take on it in the form of "Diffusion Pilot", which I gradually dissect in subsequent posts.
